Learning Serverless (and why it is hard)
Where do you start when you want to learn serverless?
I’ve been trying to figure that one out for years.
I genuinely wish I could work out how to figure this out because there has been a huge need to get developers up to speed with serverless for several years.
The lack of a clear path from “developer” or “cloud engineer” to “serverless developer/engineer/architect” is startling given that this has been on the agenda for many people in tech for years.
“Our team doesn’t understand what serverless is”
I’ve worked with small teams, bigger teams, and very big teams. Teams who have been trying to develop startup applications on the web, on mobile and for enterprise and for consumers. I’ve also worked in scenarios that have very large teams where you simply have no way of working one to one with everyone and they are building some critically important applications using a serverless approach and they could last for many years.
One thing I have learned in all this: It is not easy to get developers to change their day to day approach to development (the approach they have learned either at work, or trial and error, or via the years of building software) to switch over to a serverless approach.
Developers are simply annoying.
I mean, not all the time. If you leave them alone to do what they want, they’re often great!
But if you ask them to change… there can be problems.
They are exceptionally opinionated about the way they think applications should be built, the way they think code should work, the way that you should write code in certain programming languages…
If you get a team of 8 developers, you’ll be given at least 13 opinions on serverless simply by mentioning it, and none of them have to have any experience.
And the issue is only exacerbated by how developers think about the “cloud”. I still don’t think we have a good definition of the cloud, but it doesn’t stop a developer giving you their opinion of what is good and bad about doing things “in the cloud” and “on premise” (although… “on premises” should be right but that’s not what we say, or are we talking about having a “premise” in the context of previous statements and propositions about which we then talk… because that would be about right sometimes).
Developers are exceptionally opinionated about everything to do with tech.
And it’s really annoying.
Because, and I say this really carefully, most of the time, developers are just very clearly, and very plainly, wrong.
Where developers are right about serverless
Serverless is not easy... to learn.
At least, serverless is not something you can go to a website and learn the syntax of in half a day or type in “hello world serverless” into a search engine and get 47 “Learn Serverless with these 8 neat tricks!” blog posts, and then find out that your years of building applications in “javathon” using the “railpress” framework are easily transferrable, much like many other skills have been in the past 15 years of working on internet and server based solutions…
In fact, when most people look for tutorials or definitive guides, finding the really good information on serverless is, unfortunately, far too difficult a lot of the time.
Minor rant about “serverless.com”
The whole idea is not helped (and I’ve said this from the changing of the name back in 2016 I think it was?) the serverless.com has really not helped here.
That is not to say that they are not good people (they are and there are some great people that work there), and it is not to say that there are a number of companies that have got a lot of value out of what they produce.
The problem is that serverless.com is just as opinionated as everyone else, and that comes out in the way it builds its solutions.
Note: And if you haven’t figured it out by now there are many more ways of building serverless applications than serverless.com and anyone else that is thinking “the name of the website/company might confuse people” well, it confuses me and I often have to have conversations about when things are related to their solutions and when they are not. It’s infuriating.
Back to finding it hard to find good information on “serverless”
So how do you find information?
Back before it was popular, there were a few people who… found each other on the internet. Mainly on twitter actually.
These were people like myself, Yan Cui, Ben Kehoe, Ant Stanley, Farrah Campbell, Jeremy Daly, Erica Windisch and a whole lot more (and are as deserving as the ones I’ve just mentioned off the top of my head) who ended up getting to know each other well in a whirlwind few years between about 2015 and 2020.
We talked a lot and spoke at conferences and setup conferences like ServerlessDays.io.
And we learned from each other. And we shared the knowledge we had, and how difficult it was to figure out some of the complexities of serverless.
We had different experiences from CTOs of startups (people like me) using the approach as a backend system with small teams, all the way up to the transformation of whole enterprises to a serverless approach with hundreds of developers.
And that led to a lot of content being created and shared.
Content like the Serverless Best Practices I wrote in 2018, which are still very relevant now:
Serverless Best Practices. Within the community we’ve been… | by Paul Johnston | Medium
We all knew then, and we still know now, it is not simple to build serverless applications.
We all knew then, and we still know now, that the tools we need don’t exist for what we want to do.
We tried. There were missteps, attempts to create tools that looked like things we’d had before, attempts to create new tools that would be helpful to the solutions we were building and we learned a lot of interesting things.
We also had to deal with an unhelpful amount of misinformation being spread. The “low-code/no-code” people who, at best were gently making fun of us, but in reality were belittling what we were trying to do in many different ways.
I’m beginning to think that there is a reason for why there is a struggle there.
And I think it’s something that we’ve all overlooked.
Serverless applications aren’t easy to understand from the outside
The majority of large scale serverless applications that are in production today are on Amazon Web Services:
Serverless Computing — Amazon Web Services
Other cloud companies and other serverless solutions exist, of course, and some of them are very good. However, the solutions that have tended to become well known are the AWS based solutions, built on a base of AWS Lambda functions and using a few key principles.
And when you take a look at the solutions that have been developed, and scrutinise them, and try to find a common thread to start to explain them to other people, one thing is very clear:
Serverless systems are not easy to understand systems.
Let me rephrase that: Serverless systems are not easy to understand systems, if you only use ideas and understanding that predates serverless.
The Cynefin framework is a useful tool here. It’s a “sense making” framework. A short introduction video can be found on youtube here: Cynefin Framework — YouTube
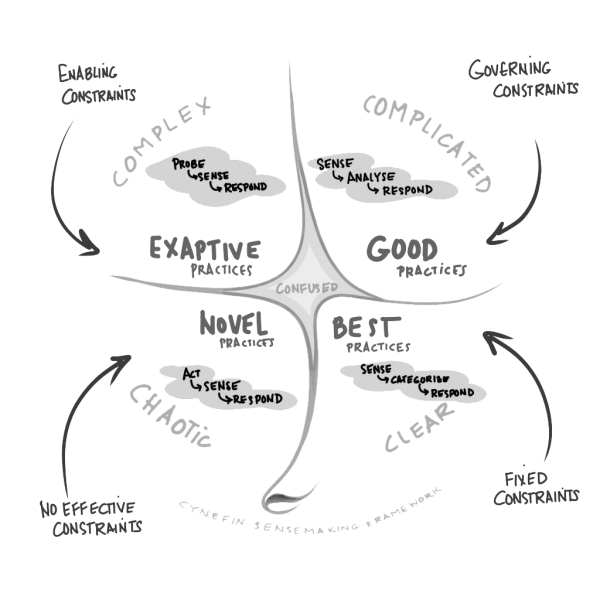
Cynefin explains that we manage and understand systems in different ways. The key is that most people do not know which of the 5 domains they are in when they are working (the centre is the 1st, or 5th, domain of confusion/disorder).
Most people are managing from within “disorder” (or confusion) because most people simply don’t consider what type of system they are working in or on actually is.
Most people simply assume that whatever system they are working on can be made to fit whatever model they like to work within. Does it need more rules, more management, more governance, more freedom?
The problem is that unless you identify the way your system works best (what domain it is in) you are likely to manage the system incorrectly.
How does Cynefin help with serverless application development?
The problem with moving to a serverless approach for developers is a very simple one:
In reality, a serverless approach is highly constrained and requires everyone to follow a few relatively simple principles over a long period of time.
In a very real sense, developers who work on serverless solutions will often complain that the serverless constraints are both confusing and are not justifiable from a technical point of view.
A simple example of some of the “constraints” might be helpful here:
My best practices from 2018 say:
- “Each function should do only one thing” and
- “use as few libraries as possible”
The AWS Well Architected Serverless Application Lens says that functions should be
- “Speedy, simple, singular: Functions are concise, short, single-purpose, and their environment may live up to their request lifecycle”.
In the AWS Lambda best practices it says
- “Minimize your deployment package size to its runtime necessities” as well as
- “Minimize the complexity of your dependencies”
Most developers I know find these best practices very confusing when they move to serverless.
After spending years having built software solutions where you can (almost) include as many libraries and dependencies in your code, these “best practices” are telling you not to.
And after spending years being told to create solutions that provide standardised and shared interfaces, and shared patterns, and classes and ORMs and all those things that people have been used to using inside and outside frameworks for years, these “best practices” are effectively telling a developer “don’t do that”.
Going back to Cynefin, the reason these exist, I would argue, is that the serverless systems we build are complicated systems and possibly in some cases complex systems.
The reason this is an important distinction to make is that most of the systems people have built up to now are essentially simple systems. I don’t mean that the technology in them is simplistic. I mean that the systems as designed could be taken and put onto other computers, and while it might be a little annoying, the reality is that those other computers could still run that software.
Caveat: I am not talking about systems that have been through multiple iterations over years, sit on a mainframe, have not been invested in or maintained properly and now the only person who understands how it works is Clive, and he’s retiring in 3 weeks. That’s bad management.
The type of systems we have all been developing for many years are the systems where you have some form of microservices architecture or “code” sits on a server/instance and interacts with a data layer.
But serverless solutions are different.
Most of the experience that a developer has had in their career will likely have been with systems that are not in the complicated or complex space and as such find acceptance of the best practices very hard.
The purpose of best practices
There is always a reason best practices exist. These practices have often been built up to sustain a particular way of working or to avoid mistakes.
The serverless best practices are, most definitely, an example of the avoidance of common mistakes.
I have worked on a lot of serverless systems and applications and have seen what developers do when they build these systems. I have seen the same avoidable mistakes made many times.
The best practices are much more about avoiding mistakes than they are about improving systems or efficiencies. Without them, systems are often slow, difficult to manage and maintain, and developers find it hard to understand what value they are getting taking the approach.
There is a purpose behind a constraint such as “minimizing the complexity of your dependency” (AWS phrasing) or “use as few libraries as possible”. The purpose behind this constraint is that an AWS Lambda function will initialise a lot faster when you constrain the dependencies and libraries.
The purpose behind “minimize your deployment package” is slightly different but has a similar outcome. When your function is first started, the deployment package has to be downloaded onto the runtime to run. The bigger it is, the longer it will take. Different runtimes (e.g. Java) are slower than others simply because they are bigger.
The purpose behind “Each function should do only one thing” and “Speedy, simple, singular” is even more difficult to explain to a developer. If your function only does one thing (singular) and you keep your code simple to understand, and you have made every attempt to ensure your code is fast, then the value you get is both in the efficiency of the invocation of the code and in the management and maintenance
These are not things that are obvious when you start to build serverless applications.
In fact, a lot of the best practices I have talked about over the years are almost completely counterintuitive.
Some may disagree with the above statement, but it is my experience with developers.
And unless a developer is prepared to accept that someone with experience and who knows what they’re talking about (e.g. someone like me or the people who put together the AWS Well Architected Serverless Application Lens would be good examples here), then it is understandable when a developer disagrees and finds it difficult to develop according to the best practices that are out there for serverless applications.
Sympathy for the Devilopers
I genuinely sympathise with a lot of developers who struggle with the switch to a serverless approach.
Switching to serverless is hard.
Switching to serverless is confusing.
Switching to serverless is counterintuitive.
The problem that I have is… I have seen what is possible with serverless.
When you understand what is possible with serverless, there is almost no technical scenario where a serverless approach is not the right one.
…and, whatever you may have read or heard from someone, the number of scenarios where a serverless approach is not appropriate is *vanishingly* small.
The number of solutions you cannot use serverless is diminishing daily.
The ones you cannot use it for is almost a rounding error to zero.
There are numerous highly regulated organisations using serverless (Banks, Pharma, etc) there are Governments, there are startups, there are everything and anything you can imagine.
Serverless came of age many years ago, is mature, and is not just about saving money by allowing companies to see how much each transaction is costing (Simon Wardley FinDev/FinOps thinking which came out of research in 2016), it is also replacing accepted cloud-based approaches for highly significant projects purely on the basis of simplifying the management and maintenance availability, scaling and at magnitudes lower cost.
Developers are soon going to have no choice but to learn about serverless applications and serverless solutions and what it entails.
So how do you teach someone to build serverless applications?
The strange thing is that… I’m not sure that you can.
At least, I’m not sure that you can very easily.
“You can lead a horse to water, but you can’t make it drink”
In my experience, a developer has to want to learn what it means to build a serverless application.
If a developer doesn’t believe that it is that important, and doesn’t listen to the best practice or take them on board, then it is almost impossible for that person to deliver a good serverless solution.
Some people have to go through that process unfortunately so that they come out the other side and realise why the best practices exist.
I have had to let developers release solutions into production, without saying anything, that I know have issues simply so that they can learn why what I have said previously to them is important.
The first step is actually the hardest: and that is getting them to start the journey.
Serverless development doesn’t lend itself to long gaps between releases.
And by “long gaps between releases” I mean anything more than a couple of weeks.
I mean, once you understand it, a couple of days is a long time in serverless!
I say this because developers learn more by doing and making mistakes, than they ever do by being told.
So, I’ve been thinking about this recently, and I think I’m coming up with a possible future approach to how we can teach serverless.
Learning Serverless: The Sweet Spot
The best serverless applications tend towards being highly event driven. I haven’t mentioned event driven architectures or EDA in this post yet, but I think it’s important to note here.
The best serverless applications also tend towards using Function-as-a-Service functions that are small, singular, fast functions. Not all serverless solutions use FaaS functions, but the majority do at present. While many people build FaaS functions, not many build whole applications, and therefore few learn the wider understanding of them.
The best serverless applications also tend towards using a low latency non-RDBMS data store. An example from AWS is DynamoDB. The reason being that the data solution was originally developed to maintain low latency at scale and these features make it an ideal fit with other characteristics of serverless solutions.
The best serverless applications also tend towards highly automated DevOps. When building AWS serverless solutions I have a preference for AWS SAM and the AWS SAM CLI, and I know others who will tell you of their preference for other solutions.
Applications rarely just happen though. It is very rare to find developers with experience of the kinds of solutions above who have not built serverless systems already.
In other words, this set of skills is unusual.
Many developers will also not have had experience of the range of skills outlined here, unless they have been the lone tech person on a small startup or something similar to that. It is unusual, especially in a larger company, for someone to have that kind of responsibility across all the disciplines.
And that is why it is so hard to find developers who are “serverless ready”, and you have to train them.
But there is a sweet spot.
And the sweet spot appears to be in the combination of three elements:
Event-driven thinking + “Speedy, Simple, Singular” Functions + Low Latency Data Layer development
The DevOps parts are, I think, the easiest elements to learn as you go, especially with a tool like SAM.
If a developer is prepared to accept the “Speedy, Simple, Singular” functions side of serverless, then they have already accepted probably the hardest concept in the whole of the best practices.
The data layer is not something that is easy to learn, but it is also not impossible. There are some very good resources out there for example for DynamoDB, for MongoDB and the support forums and networks are bigger than the serverless networks. In my view, all someone needs, is the understanding that “RDBMS” are not the only way to do data layers, and everything else can flow from there.
Event driven architecture (EDA) and thinking is possibly the hard one here. I’ve worked with people who think they understand EDA and bring preconceived ideas into serverless. EDA systems aren’t serverless, so bringing the ideas across that way doesn’t entirely make sense. However, FaaS functions such as AWS Lambda are almost always invoked by an event occurring. That makes events a really important managed subsystem to a serverless solution and understanding the different patterns that emerge from that can make a massive difference to the applications that can be developed.
That sweet spot, the event-driven, small-function, low-latency-data, sweet spot, that is where your serverless developers come from.
If a developer doesn’t at least grasp those concepts and accept that as a starting point, then it is arguable that what they are developing is not serverless but is an extension of non-serverless development on technologies intended for serverless.
Learning Serverless is hard but getting easier
All in all, learning serverless is hard.
The best way to learn is to do. Trying to build something serverless without the support of the community or certain tools has been very hard for years due to the lack of clear support and direction.
Hopefully that is changing.
The best serverless solutions are still AWS-based.
The best serverless solutions, I think, will stay cloud based as well. I’m not sure I see, at this point, many emerging solutions that I could genuinely call “serverless” that do not look something like AWS Lambda, DynamoDB, API Gateway, SQS and the other services that go with it.
I wish I could say that the other cloud providers have caught up in recent years. There have been some interesting service improvements, but AWS has worked very hard to develop joined up services.
The service that allows AWS to make the serverless solutions all work together is, believe it or not, Identity and Access Management (IAM). I have often heard how other cloud provider’s solutions are “better”, but I simply don’t see it. AWS has worked exceptionally hard to make their solution work. It is functional, understandable, and works. You can keep the bells and whistles.
“But what is a serverless solution?” (I hear you ask)
That is for another post.
But it is not defined by its technology.
It’s a strange thing to say, but that is true for me.
Although almost all serverless solutions come back to AWS Lambda, DynamoDB and API Gateway, they do not have to.
Now, in 2022, a serverless solution is one that is the easiest to run, for the least amount of effort, and still provides me with the required business value at the lowest (reasonable) cost.
My AWS bill is rarely above $5 a month, and I do a decent amount of trying new things.
My experiments are almost always a variation of using the AWS SAM CLI to throw together a set of AWS resources, usually API Gateway, AWS Lambda functions, events, SQS queues, SNS, EventBridge, DynamoDB, and maybe S3 here and there with other resources every now and again. I almost always build and tear down the resources every session. There’s not a lot I leave up and running, and even when I forget, it’s rare for it to cost me anything.
I’ve been running my AWS account like this or a variation of this for 7 or 8 years now. The most expensive thing on my account is some files I have on S3.
I reckon I’ve probably got the initial proof of concept somewhere for the original backend for the startup I joined in 2015. It’s probably very bad.
But I reckon it would still work.
And I reckon it would still be able to manage the load for a good few thousand people.
And it was AWS Lambda based.
And I can run all this at far far less than the cost of an EC2 server, and it’s all automated and managed for me.
Go and learn serverless. It’s never been easier.
